すべての撮影をタグ付け。手作業はゼロ。
VisionTaggerはオンデバイスAIで撮影全体のキーワード、キャプション、XMPサイドカーを生成 — Lightroom、Capture One、Photo Mechanicにすぐ取り込み可能。アップロード不要、画像単位の課金なし。
macOS 26 の Apple Silicon Mac が必要
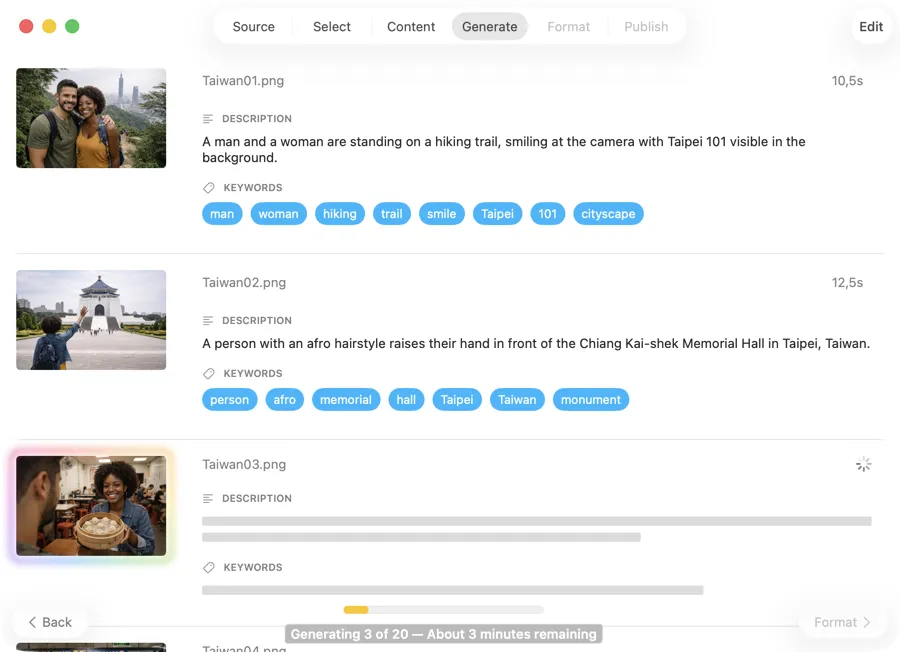
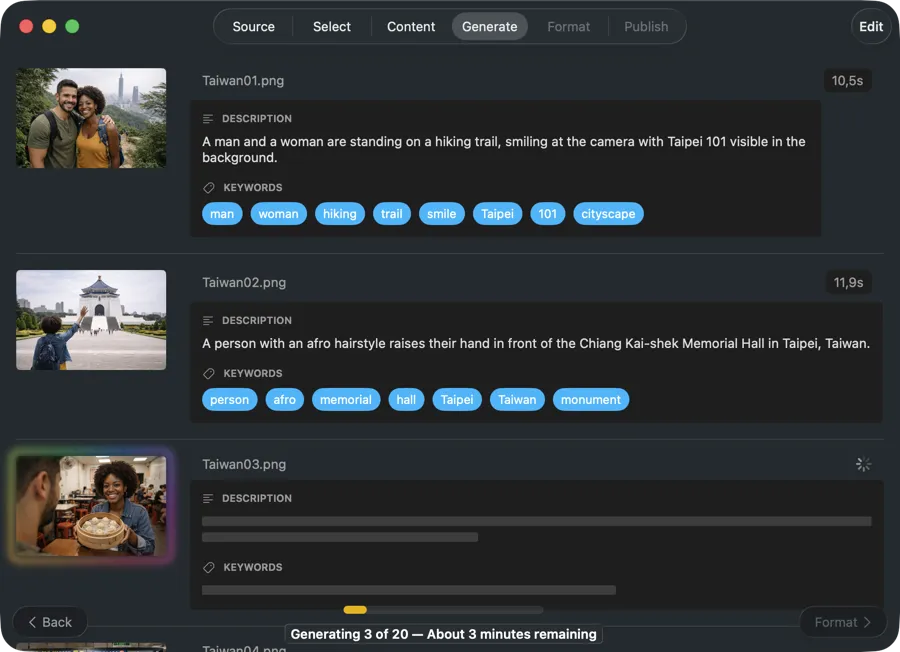
撮影は積み重なる一方。あとで写真を見つけるのが大変であるべきじゃない。
撮影のたびに何百、何千というファイルが残る。数週間後にはフォルダをスクロールして一枚の画像を探している。手動のキーワード付けは何時間もかかり、結果にばらつきが出る。クラウドのタグ付けツールはクライアントの仕事を他社のサーバーにアップロードすることになり、画像ごとに毎回課金される。
次の撮影に進む間にAIが写真をタグ付け
VisionTaggerが画像をローカルで解析し、キーワード、キャプション、構造化メタデータを一括生成。XMPサイドカーをカタログワークフローに直接書き出し、Finderタグで素早く検索、または写真アプリに書き戻し — ファイルを一つもアップロードせず、画像単位の課金もなし。
撮影全体を一度にまとめて処理
JPEG、PNG、RAW、その他の一般的なフォーマットのエクスポートが入ったフォルダをドロップするか、写真アプリから画像を選択。VisionTaggerが一回の実行ですべての画像にメタデータを生成するので、ファイルを一つずつ開いてタグ付けする必要がない。
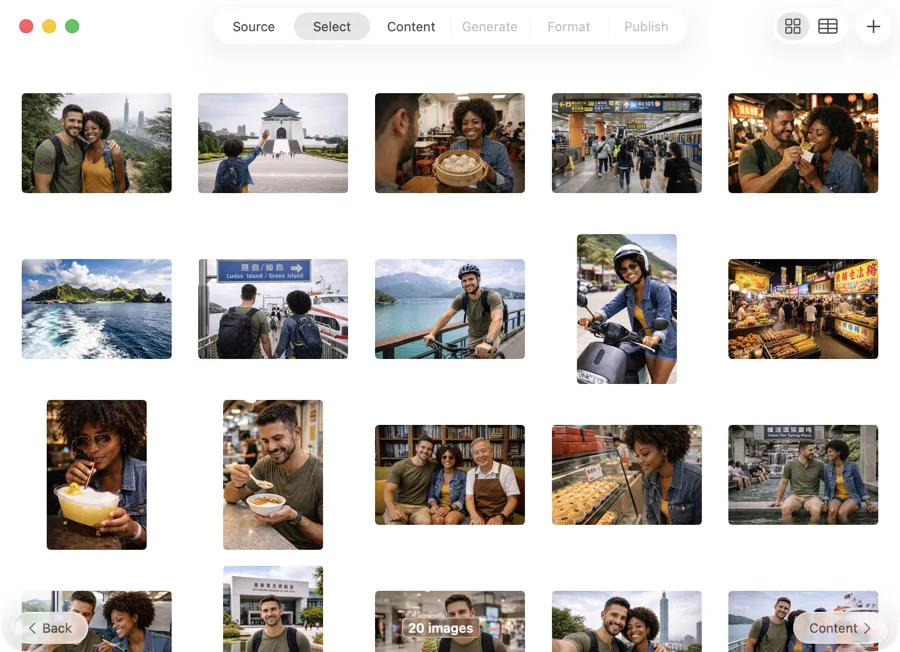
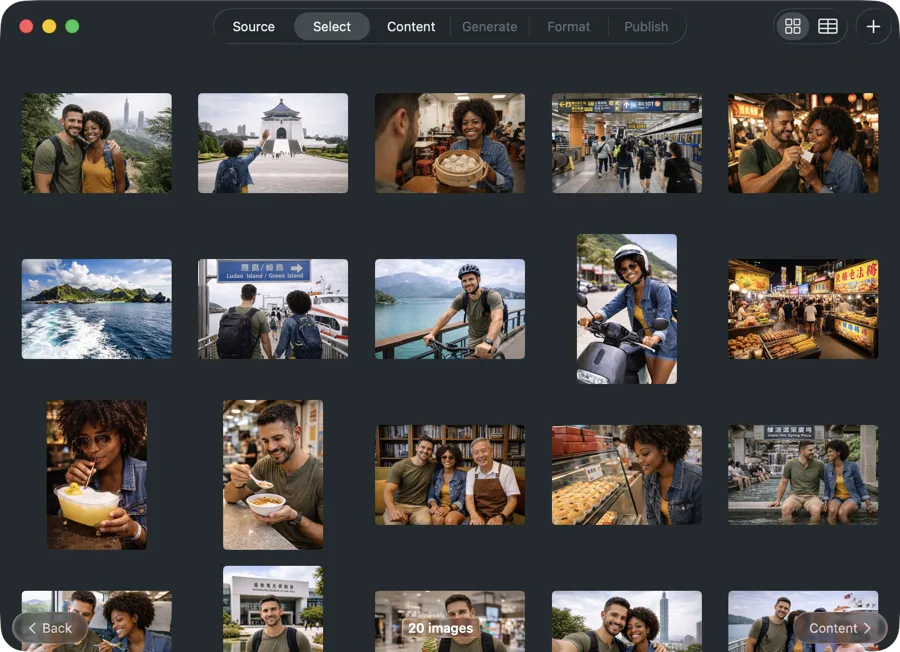
ワークフローに合ったメタデータを取得
一般的なキーワードにとどまらない。被写体、ロケーション、ムード、ライティング、構図、カラーパレットなどのフィールドを定義。スキーマをプリセットとして保存し、撮影ごとに再利用して一貫性のある検索可能な結果を得る。
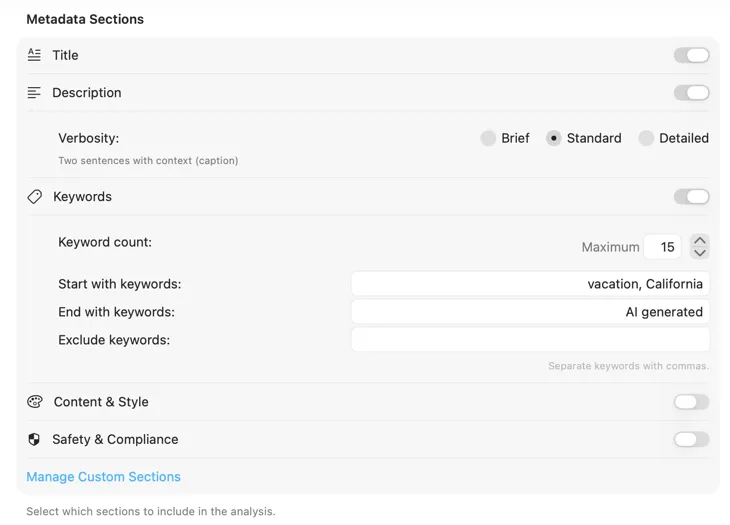
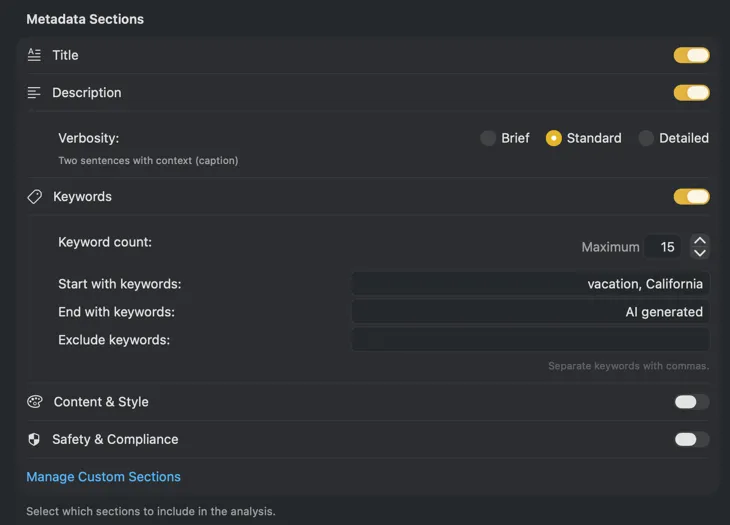
メタデータがそのままカタログに入る
Lightroom、Capture One、Photo Mechanic、Bridgeに表示されるXMPサイドカーファイルを書き出し。アーカイブパイプラインやポートフォリオツール向けにJSON、CSV、TXTをエクスポート。Finderタグを適用してSpotlightですぐに検索 — すべて一回の実行で。
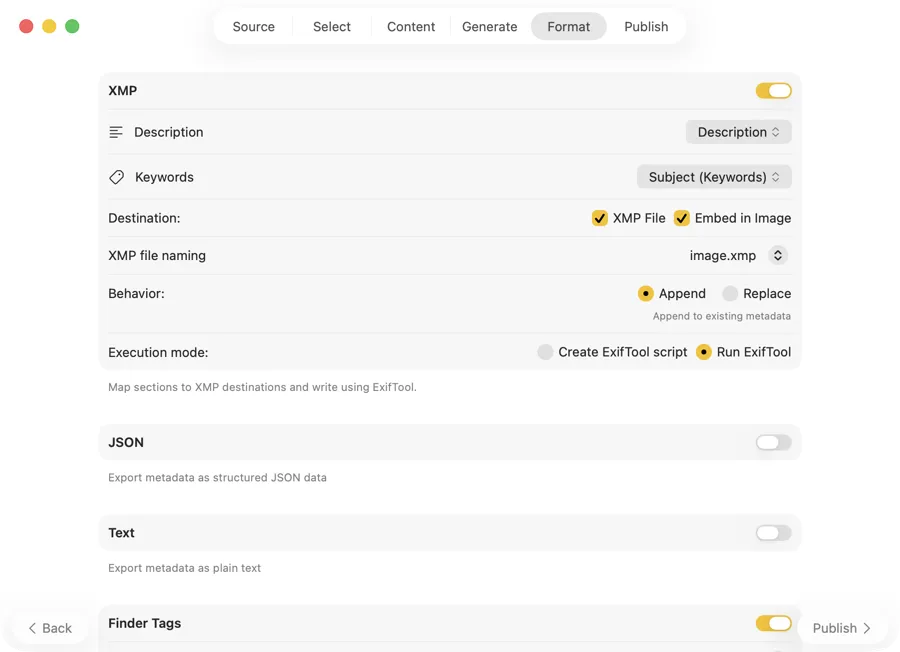
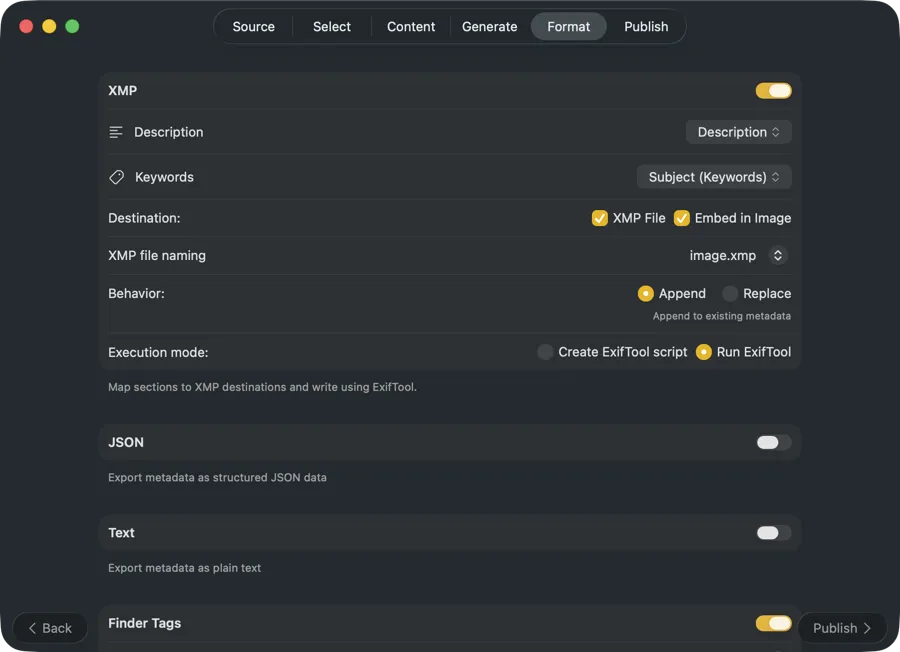
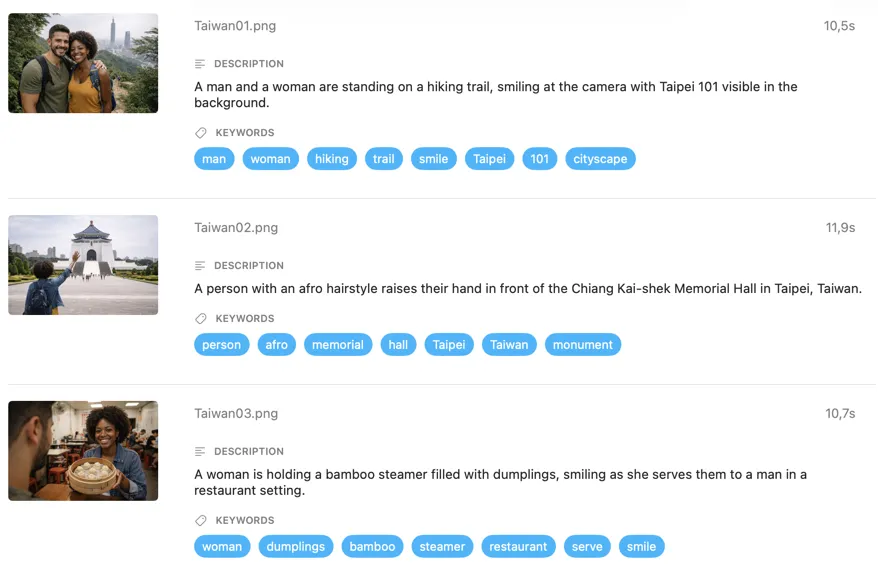
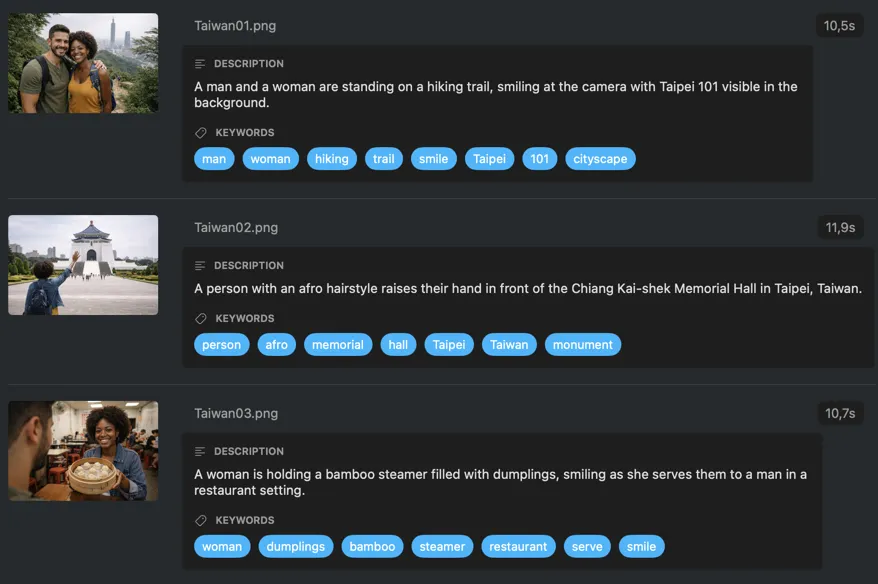
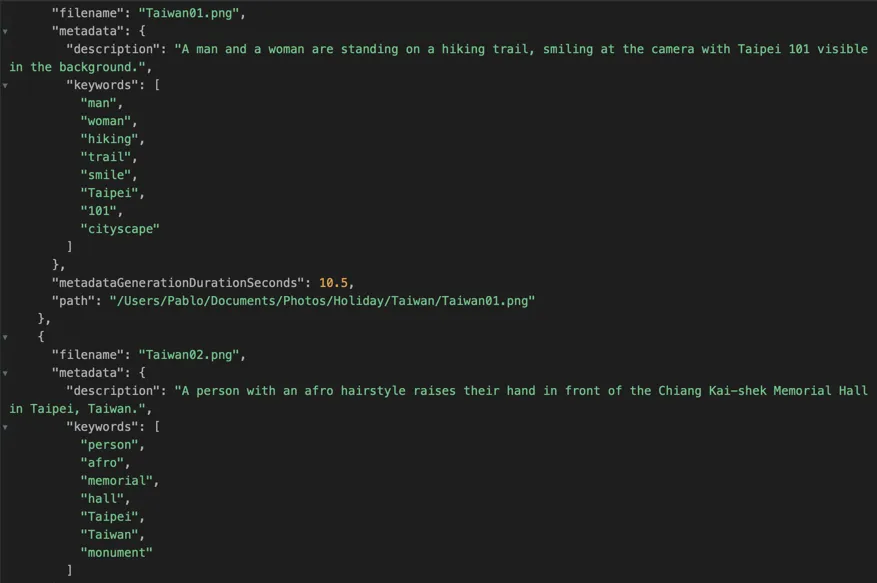
例

買い切り
VAT込み
FastSpring による安全な決済