Nunca mais tagueie fotos manualmente.
O VisionTagger usa IA no dispositivo para gerar títulos, descrições, palavras-chave e mais para as tuas imagens — em lote, sem envios e sem custos por imagem.
Requer um Mac Apple Silicon com macOS 26


Para quem é o VisionTagger?
-
Designers a pesquisar entre assets de projetos — etiquetam imagens por mood, estilo, tema e utilização para tornar a biblioteca de assets instantaneamente pesquisável.
-
Investigadores e arquivistas a preservar coleções — criam metadados estruturados e consistentes para datasets, registos e preservação digital a longo prazo.
Resultados mais inteligentes com contexto que já tens
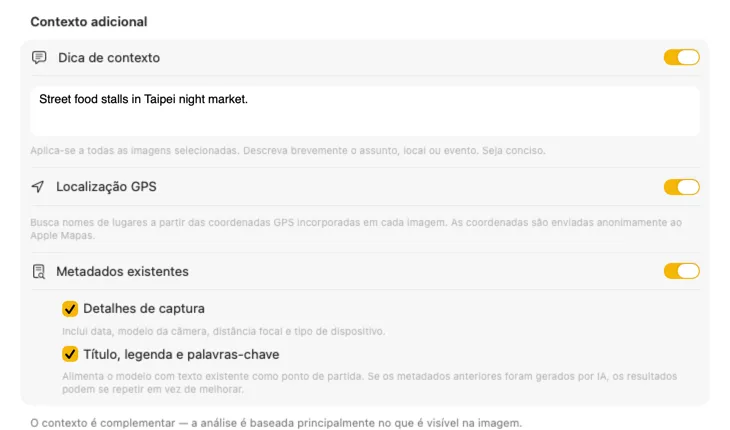
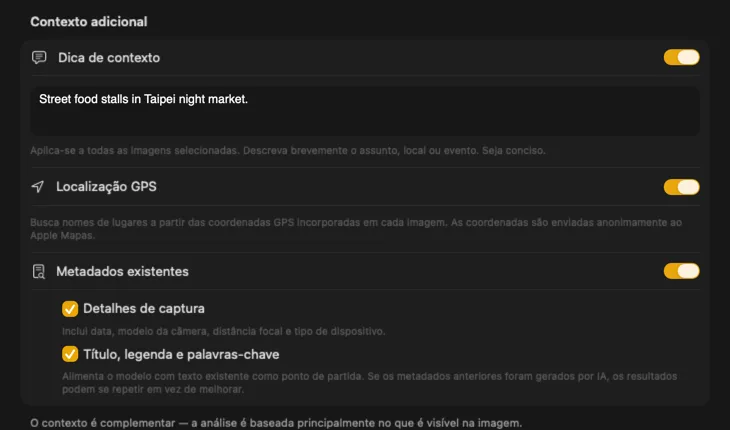
Diz à IA o que está a ver e os resultados melhoram drasticamente. Adiciona um Context Hint como “fotos de produto para uma loja de móveis vintage”, ativa GPS Location para incluir nomes de locais a partir de coordenadas incorporadas, ou passa metadados de câmara e editoriais já presentes nos teus ficheiros. Cada fonte é opcional e é inserida diretamente no prompt — para que a IA não tenha de adivinhar.
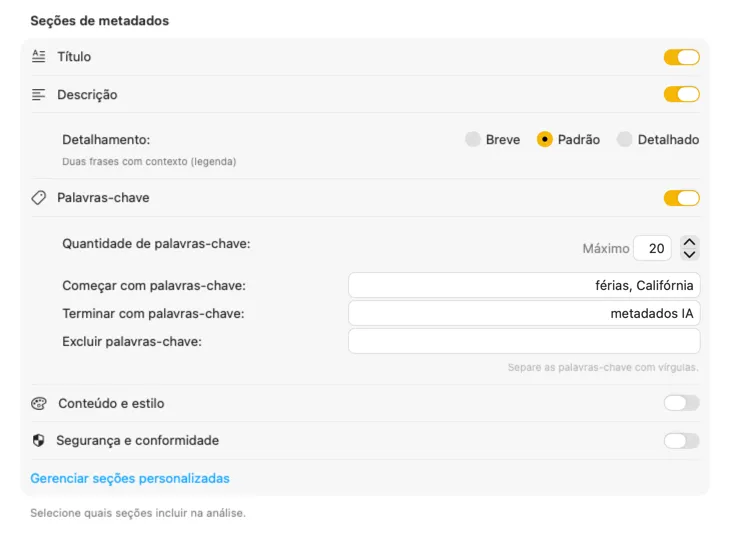
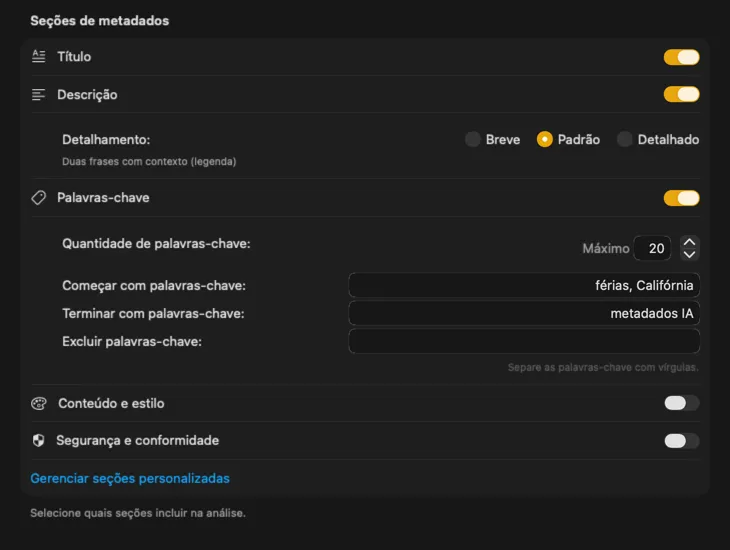
Gera exatamente os metadados de que precisas
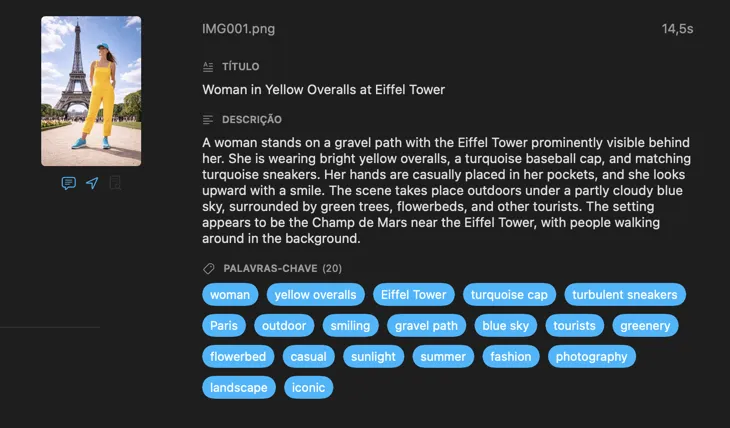
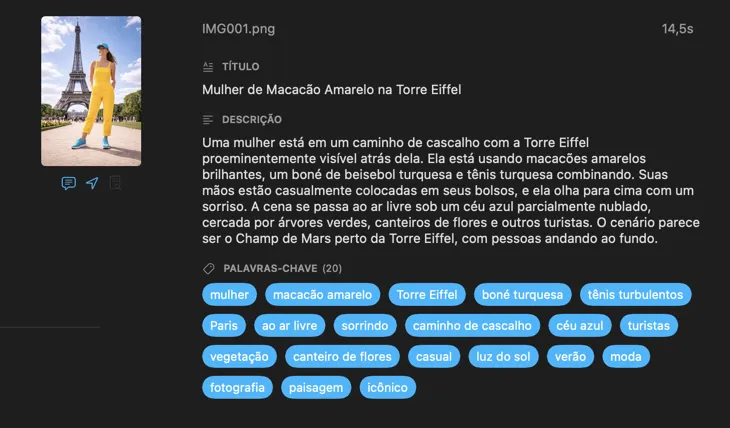
Começa com os campos que a maioria das pessoas precisa — Título, Descrição e Palavras-chave — e depois vai mais longe com Conteúdo e Estilo, Segurança e Conformidade, ou adiciona secções inteiramente personalizadas com os teus próprios campos e prompts. Precisas do output noutra língua? O VisionTagger pode traduzir automaticamente os metadados gerados usando a tradução integrada do macOS. O resultado são metadados estruturados e consistentes em milhares de fotos.
Encaixa perfeitamente no teu fluxo de trabalho
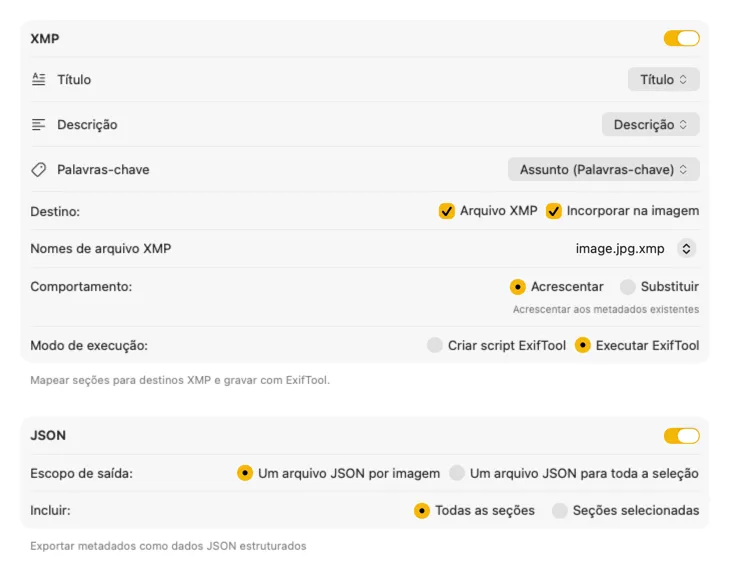
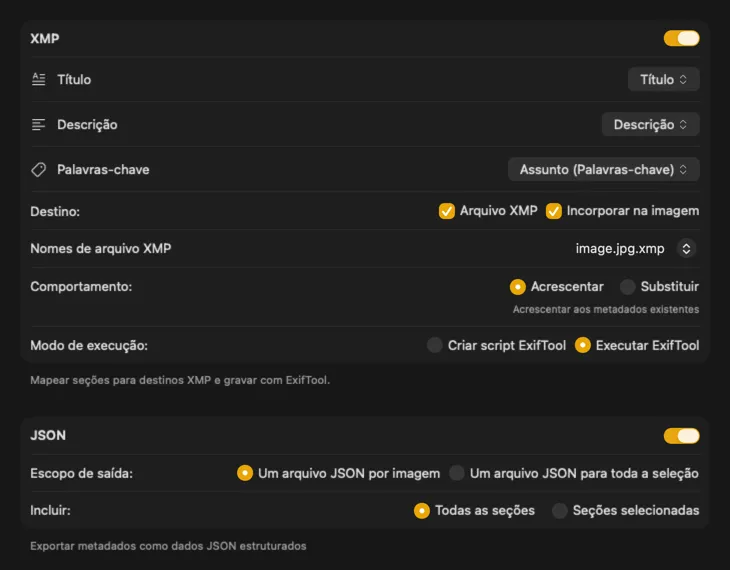
Para sidecars XMP e metadados incorporados, o VisionTagger integra-se com o ExifTool — um utilitário padrão da indústria, amplamente confiável. Os teus metadados vão aparecer em apps como Adobe Lightroom, Bridge, Capture One, Photo Mechanic e qualquer outro software que leia XMP. Escreve de volta na tua Biblioteca de Fotos, exporta JSON, CSV ou TXT por imagem, ou gera um único ficheiro para uma execução inteira. Adiciona etiquetas do Finder para organização rápida no macOS. Seleciona vários outputs de uma vez e configura-os em conjunto — para que uma única passagem de geração alimente todos os destinos que usas.
Automatiza e esquece
Duas ações de Atalhos — uma para ficheiros no Finder, outra para a tua Biblioteca de Fotos — permitem-te correr o processo completo em segundo plano sem abrir a app. Configura uma automatização de pasta, uma ação rápida do Finder, ou aciona pela linha de comandos. Usa as definições atuais da app ou fornece um preset guardado para resultados reproduzíveis de cada vez.

Como funciona
Ver demo no YouTube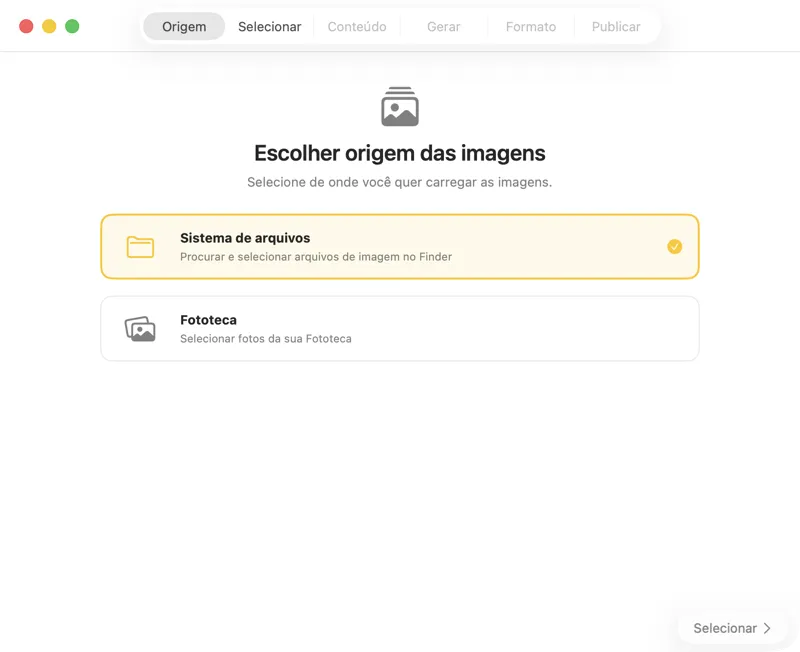
Escolhe onde as tuas imagens estão guardadas — pastas no teu Mac ou a tua Biblioteca de Fotos.
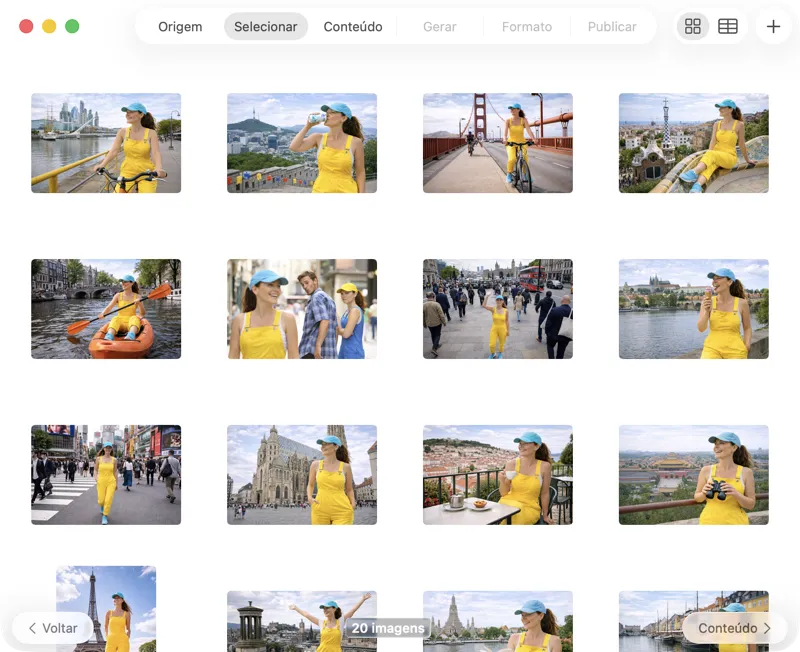
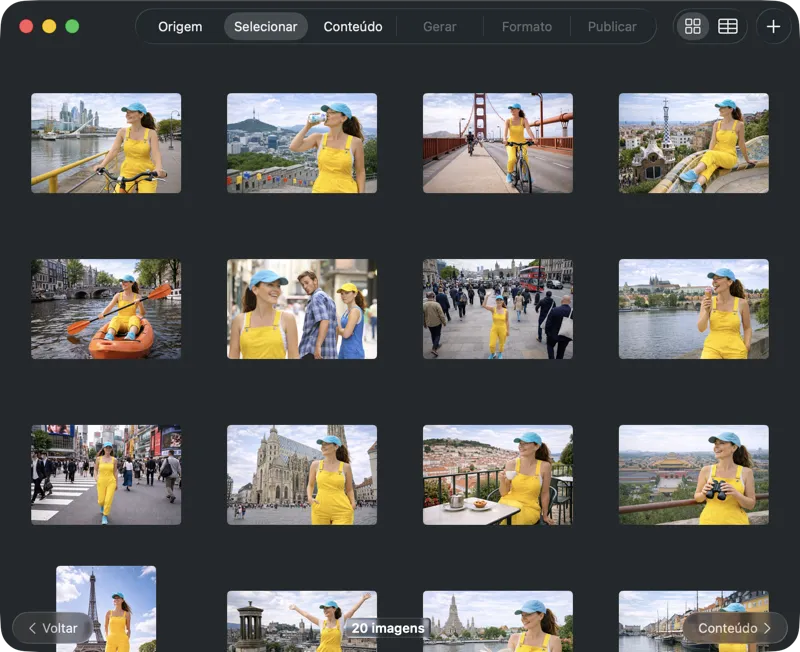
Escolhe exatamente o que queres processar. Vê a tua seleção em grelha ou em tabela, adiciona mais imagens pelo botão de adicionar, ou arrasta e larga ficheiros na app para criar um lote.
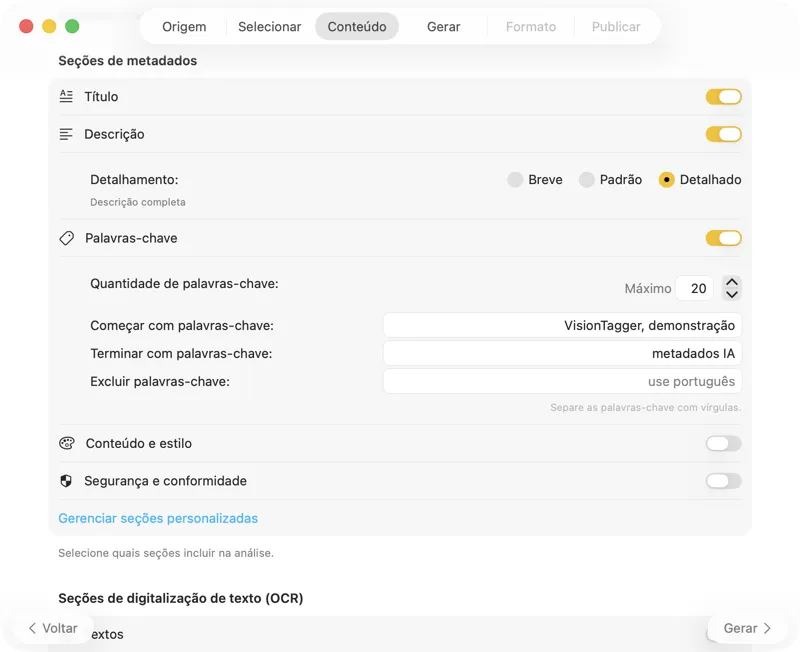
Escolhe um modelo de IA (descarrega um na app com um clique) e decide que metadados gerar: títulos, descrições, palavras-chave, tags de estilo, classificações de segurança, ou os teus próprios campos personalizados.
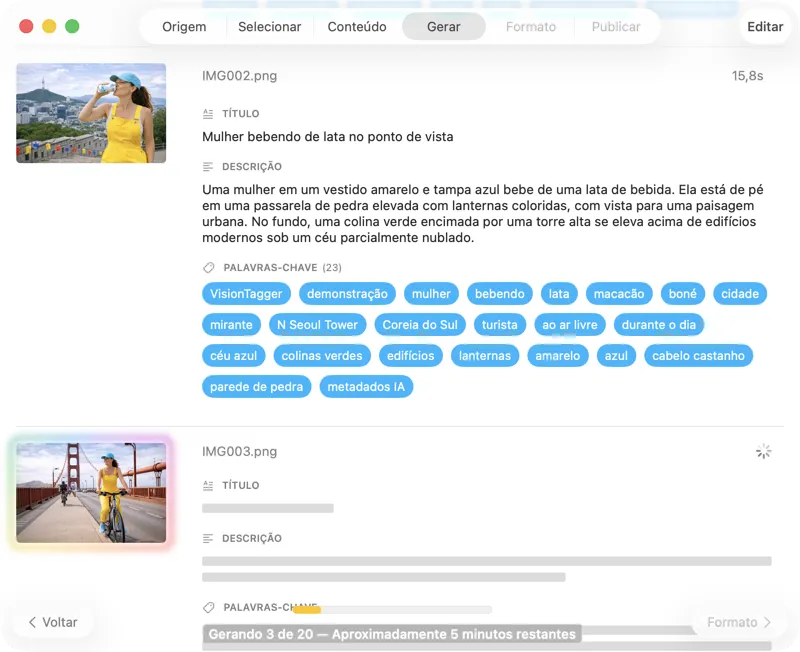
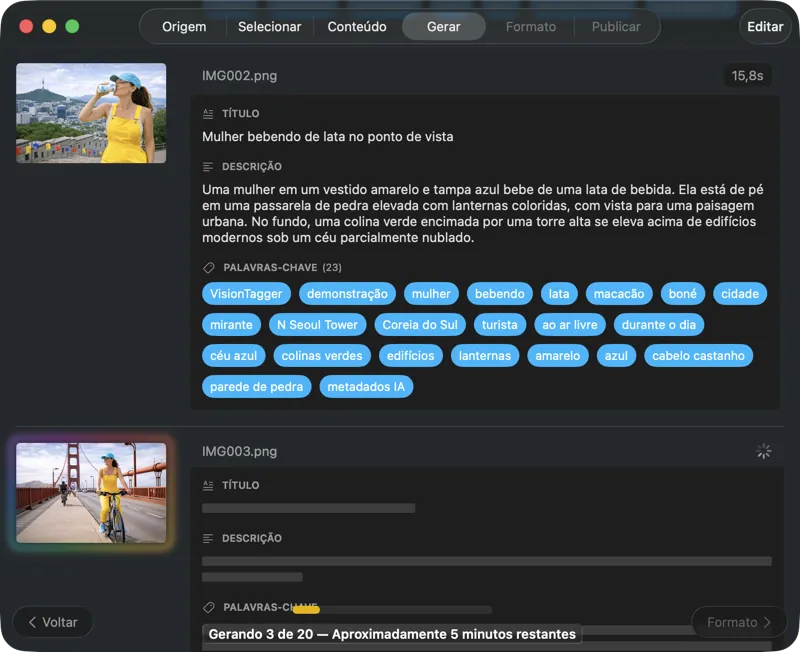
Vê os resultados a aparecer em tempo real. O VisionTagger processa as imagens localmente e vai enviando os metadados gerados para uma lista com scroll assim que cada item fica pronto, para poderes rever e editar os outputs enquanto o lote continua.
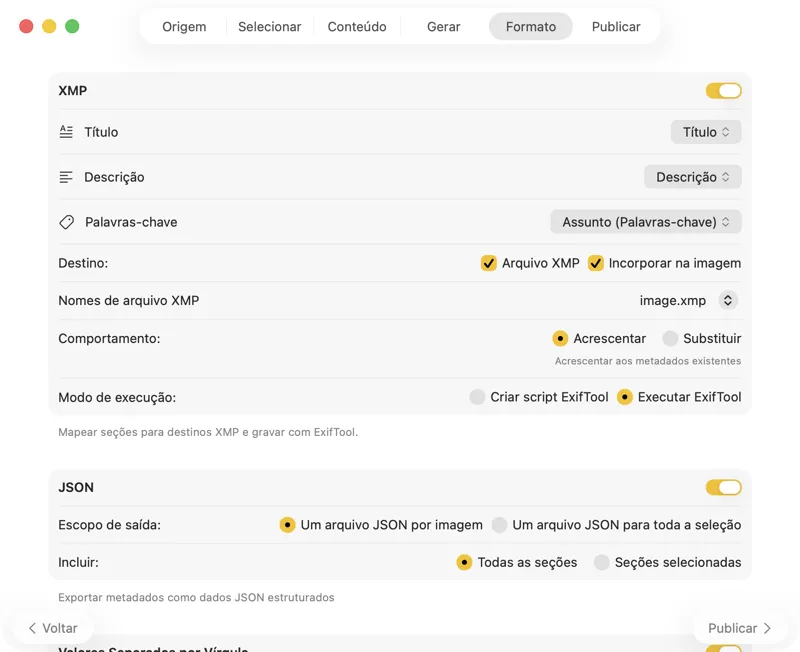
Escolhe para onde vão os metadados: sidecars XMP para o teu catálogo de fotos, JSON ou CSV para a tua pipeline web, etiquetas do Finder, ou escreve de volta no Fotos. Seleciona vários outputs de uma vez.
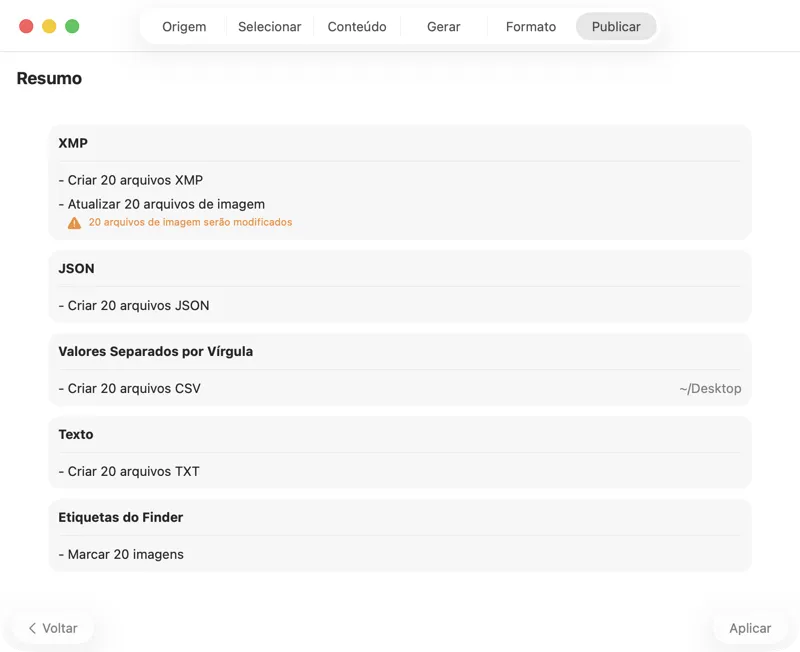
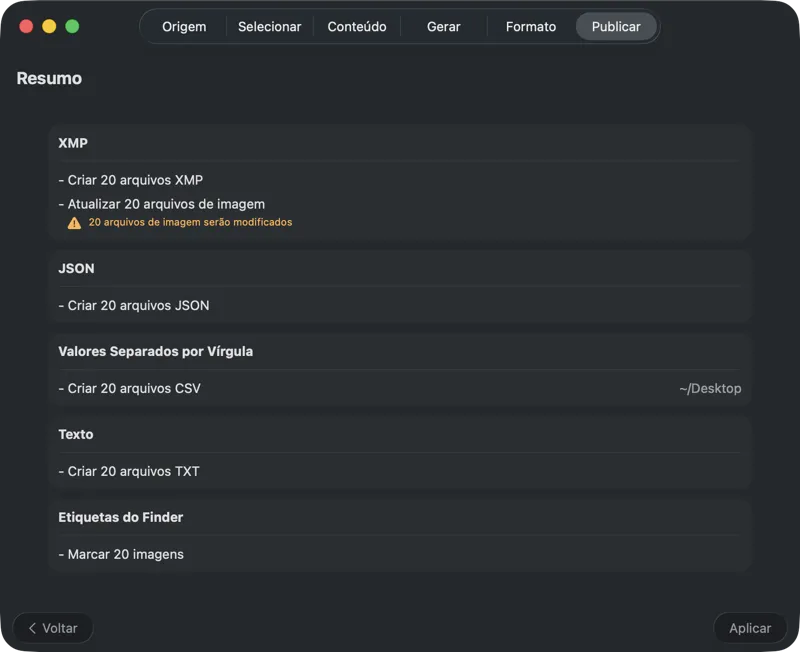
Confirma antes de escreveres seja o que for. Revê um resumo claro de todas as ações que vão ser executadas, incluindo avisos quando ficheiros ou metadados existentes puderem ser sobrescritos — e depois publica para aplicares os outputs selecionados com confiança.
Compra única
IVA incluído (exceto US & CA)
Pagamento seguro via FastSpring