Nooit meer handmatig foto’s taggen.
VisionTagger gebruikt on-device AI om titels, beschrijvingen, trefwoorden en meer te genereren voor je afbeeldingen — in bulk, zonder uploads en zonder kosten per afbeelding.
Vereist Apple Silicon Mac met macOS 26
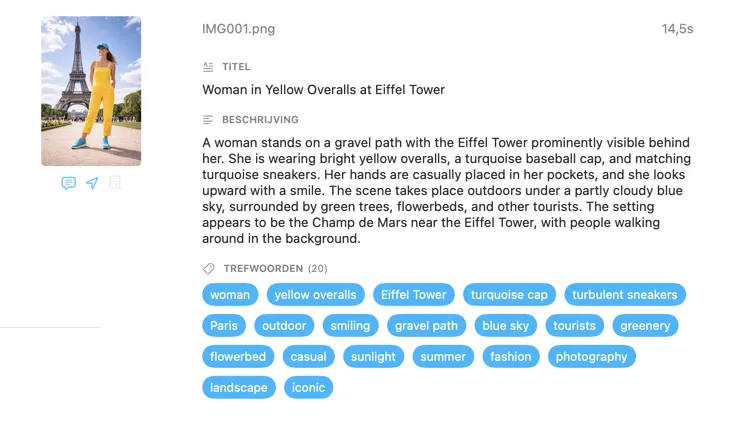
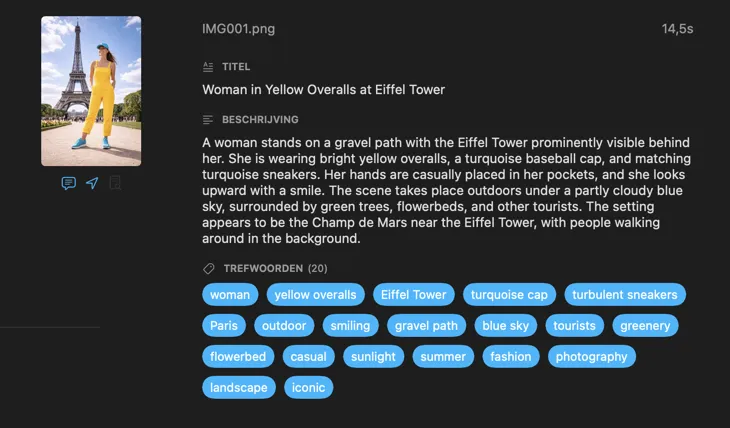

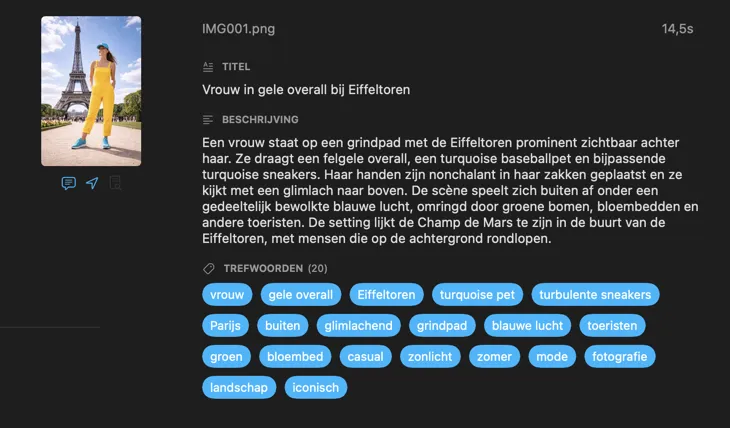
Voor wie is VisionTagger?
-
Designers die zoeken in projectbestanden — tag afbeeldingen op sfeer, stijl, onderwerp en gebruik om je asset-bibliotheek direct doorzoekbaar te maken.
-
Onderzoekers en archivarissen die collecties bewaren — maak gestructureerde, consistente metadata voor datasets, archiefstukken en langdurige digitale bewaring.
Slimmere resultaten met context die je al hebt
Vertel de AI waar het naar kijkt en de resultaten worden aanzienlijk beter. Voeg een Contexthint toe zoals “productfoto’s voor een vintage meubelwinkel”, schakel GPS-locatie in om plaatsnamen op te zoeken via ingebedde coördinaten, of geef camera- en redactionele metadata mee die al in je bestanden staan. Elke bron is optioneel en wordt direct in de prompt opgenomen — zodat de AI niet hoeft te raden.
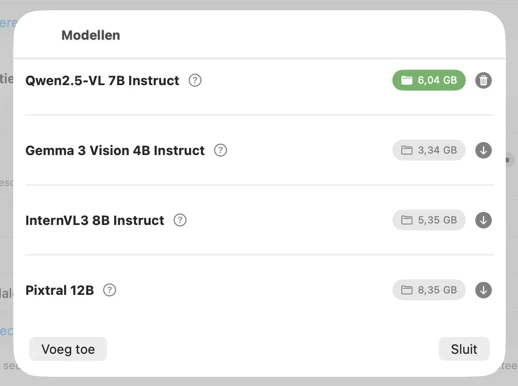
Genereer precies de metadata die je nodig hebt
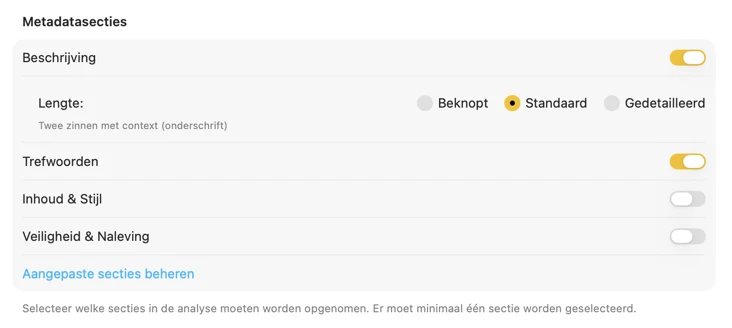
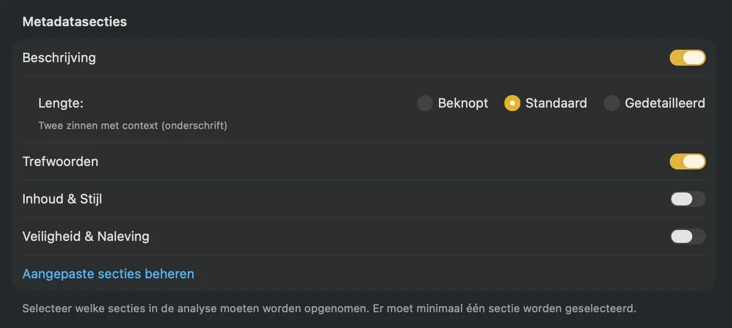
Begin met de velden die de meeste mensen nodig hebben — Titel, Beschrijving en Trefwoorden — en ga verder met Inhoud & Stijl, Veiligheid & Compliance, of voeg volledig eigen secties toe met je eigen velden en prompts. Heb je output in een andere taal nodig? VisionTagger kan gegenereerde metadata automatisch vertalen met de ingebouwde vertaalfunctie van macOS. Het resultaat is gestructureerde, consistente metadata voor duizenden foto’s.
Past naadloos in je workflow
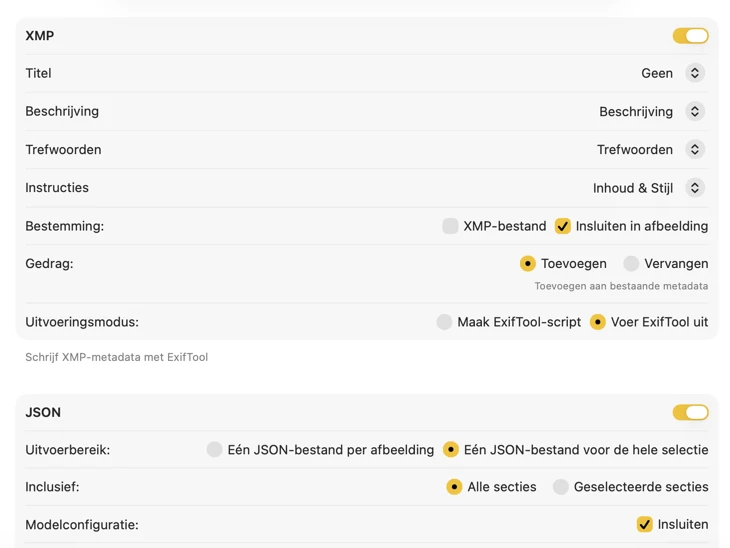
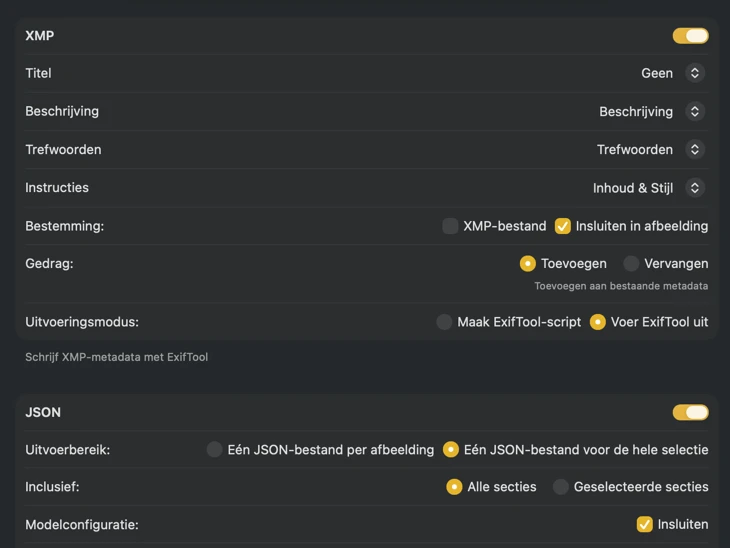
Voor XMP-sidecars en embedded metadata integreert VisionTagger met ExifTool — een industriestandaard en breed vertrouwde tool. Je metadata verschijnt in apps zoals Adobe Lightroom, Bridge, Capture One, Photo Mechanic en alle andere software die XMP leest. Schrijf terug naar je Foto’s-bibliotheek, exporteer JSON, CSV of TXT per afbeelding, of genereer één bestand voor een volledige run. Voeg Finder-tags toe voor snelle organisatie in macOS. Selecteer meerdere outputs tegelijk en configureer ze samen — zodat één generatiepass elke bestemming kan vullen die je gebruikt.
Automatiseer het en vergeet het
Twee Opdrachten-acties — één voor bestanden in Finder, één voor je Foto’s-bibliotheek — laten je het volledige proces op de achtergrond uitvoeren zonder de app te openen. Stel een mapautomatisering in, een Finder-snelactie, of activeer het via de opdrachtregel. Gebruik de huidige instellingen van de app of lever een opgeslagen preset aan voor elke keer herhaalbare resultaten.

Hoe het werkt
Bekijk demo op YouTube
Kies waar je afbeeldingen zijn opgeslagen — mappen op je Mac of je Foto’s-bibliotheek.
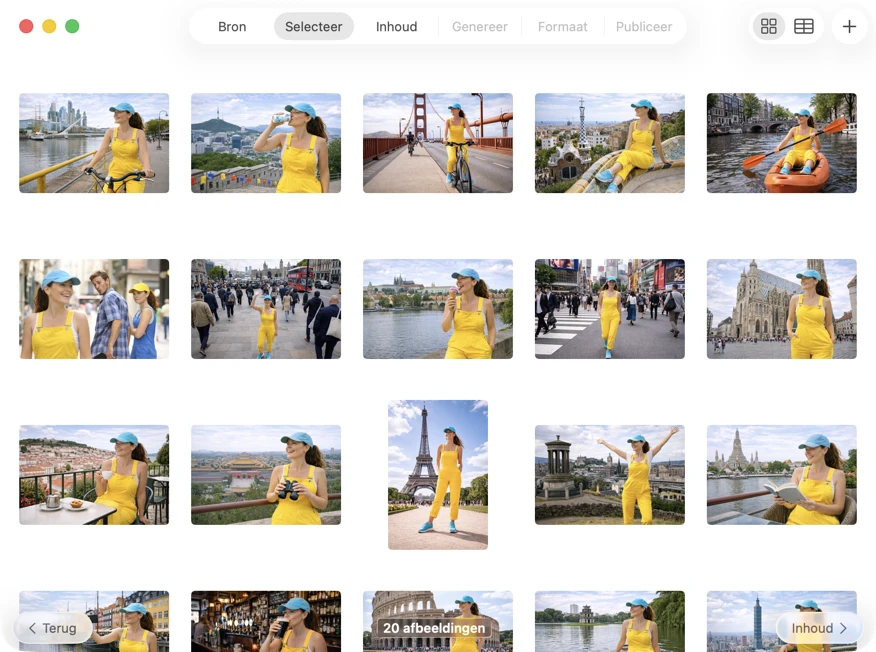
Kies precies wat je wilt verwerken. Bekijk je selectie in raster- of tabelweergave, voeg extra afbeeldingen toe via de toevoegen-knop of sleep bestanden naar de app om een batch samen te stellen.
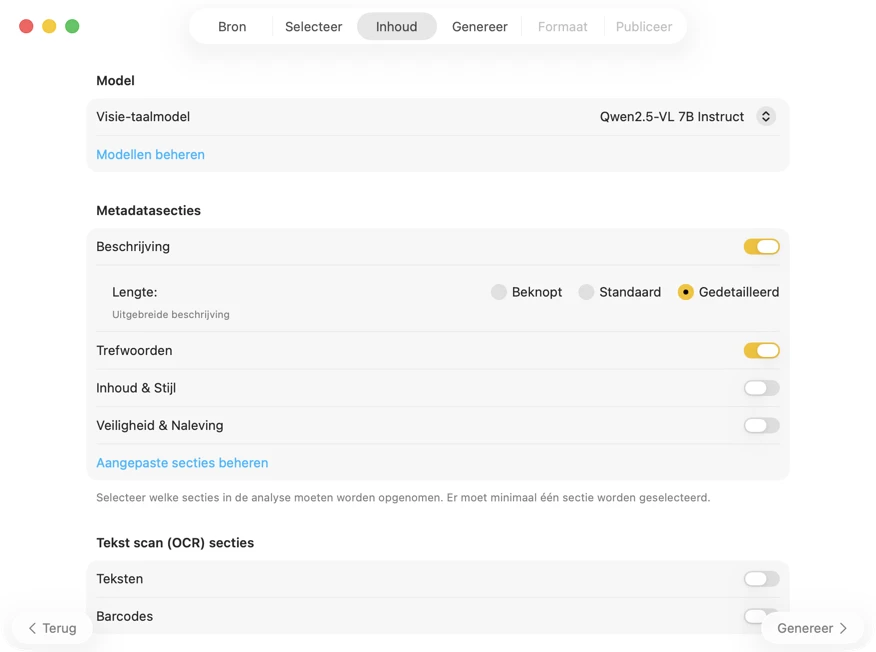
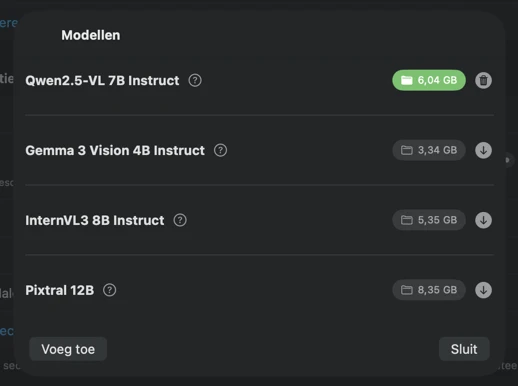
Kies een AI-model (download er een in de app met één klik) en bepaal welke metadata je wilt genereren: titels, beschrijvingen, trefwoorden, stijltags, veiligheidsbeoordelingen of je eigen aangepaste velden.
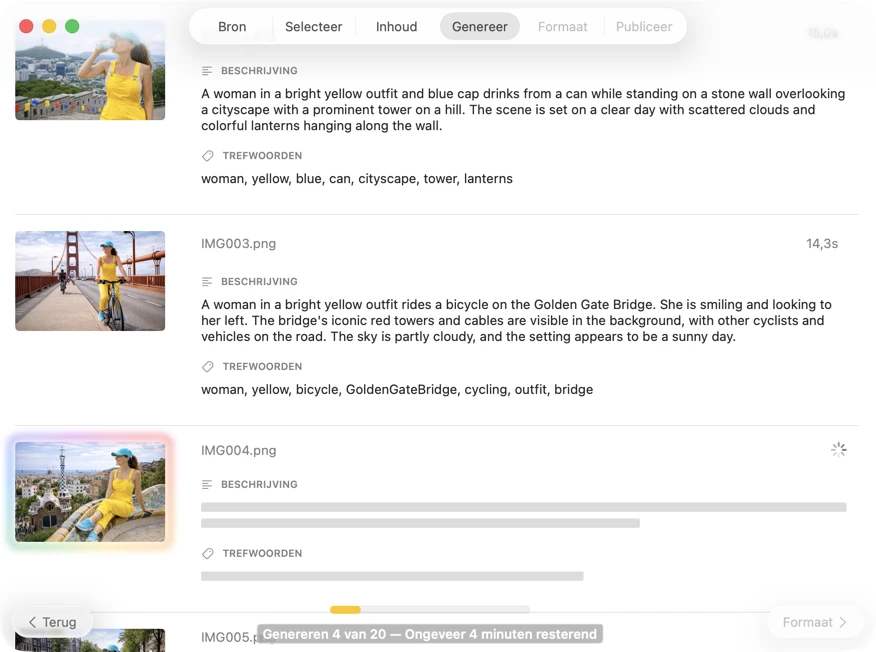
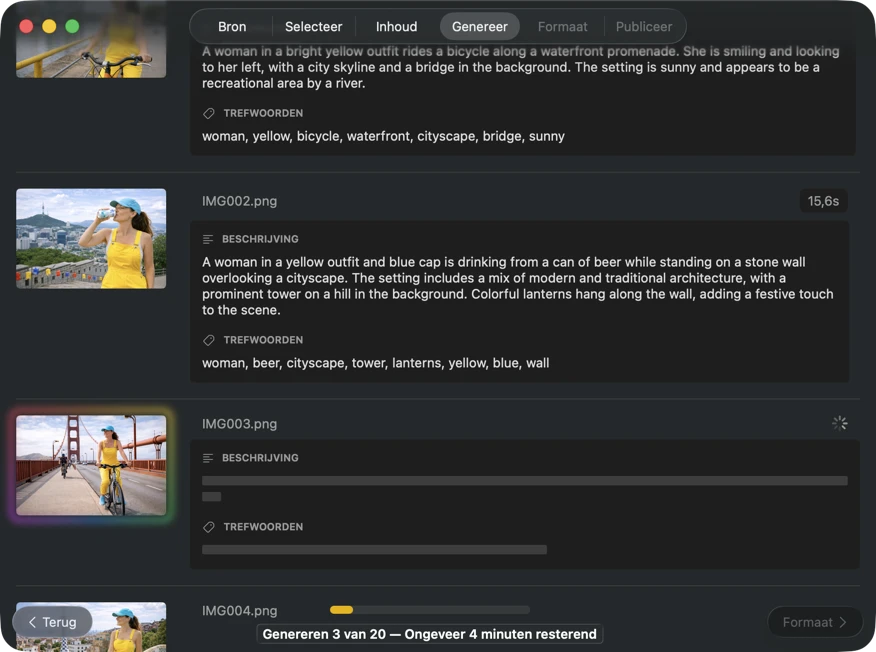
Zie resultaten in realtime verschijnen. VisionTagger verwerkt afbeeldingen lokaal en streamt gegenereerde metadata naar een scrollende lijst zodra elk item klaar is, zodat je outputs kunt beoordelen en bijwerken terwijl de batch doorgaat.
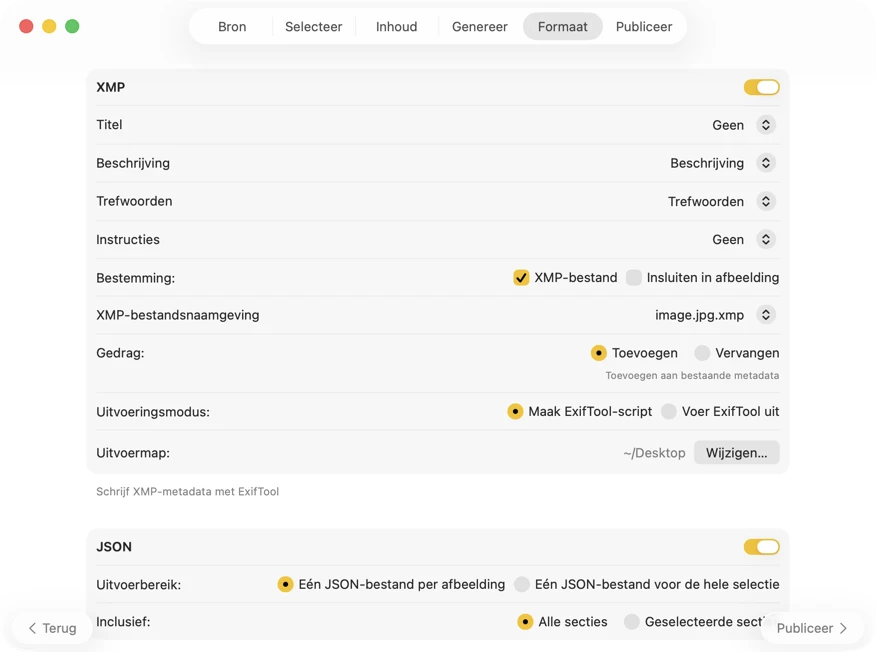
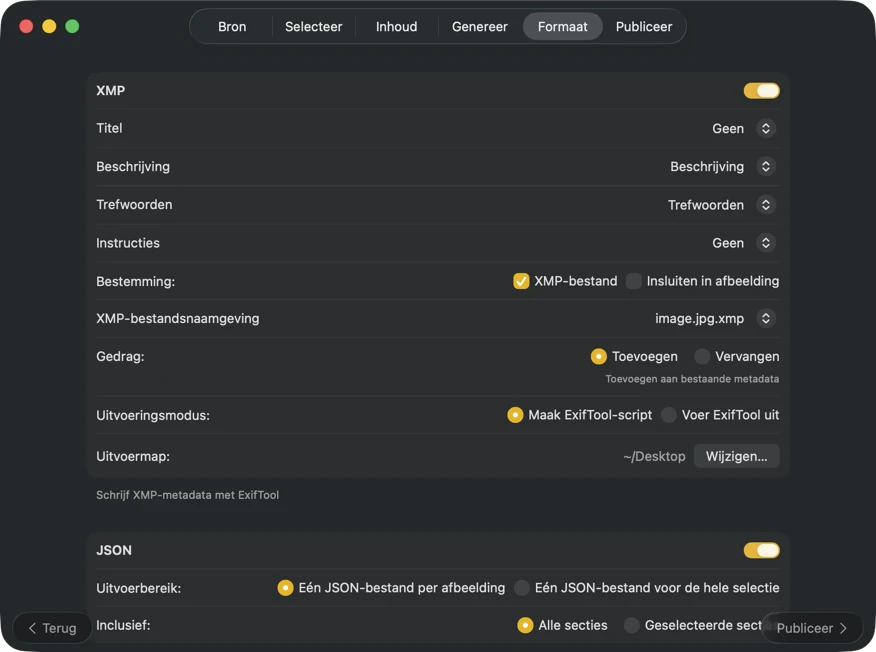
Kies waar metadata naartoe gaat: XMP-sidecars voor je fotocatalogus, JSON of CSV voor je websitepipeline, Finder-tags, of schrijf terug naar Foto’s. Selecteer meerdere outputs tegelijk.
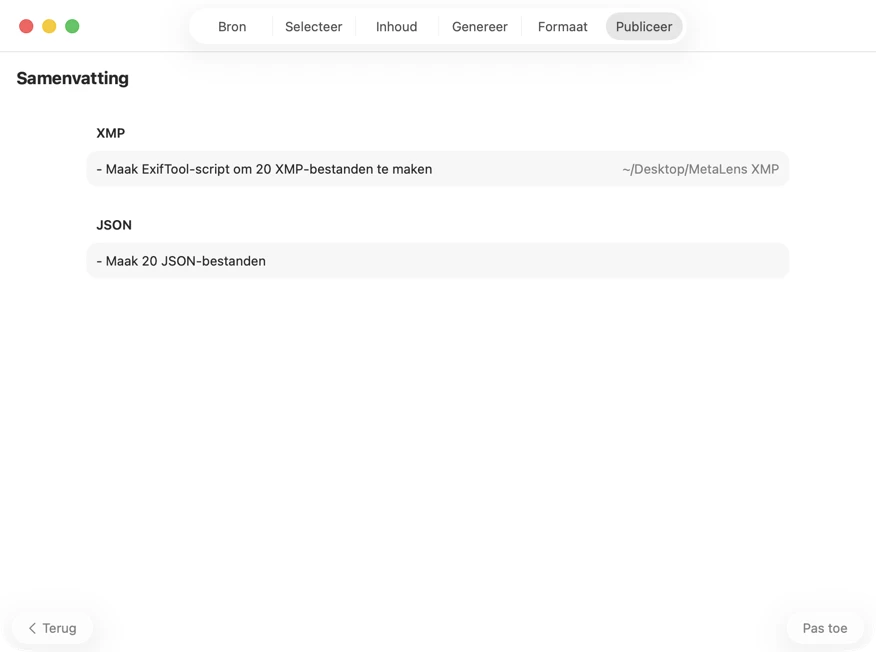
Bevestig voordat er iets wordt weggeschreven. Bekijk een duidelijke samenvatting van alle acties die worden uitgevoerd, inclusief waarschuwingen wanneer bestaande bestanden of metadata kunnen worden overschreven — en publiceer daarna om je geselecteerde outputs met vertrouwen toe te passen.
Eenmalige aankoop
Inclusief BTW
Veilig betalen via FastSpring